
Tracing API and ABI: surfaces and stability
This document describes the API and ABI surface of the Perfetto Client Library, what can be expected to be stable long-term and what not.
In summary
- The public C++ API in
include/perfetto/tracing/is mostly stable but can occasionally break at compile-time throughout 2020. - The C++ API within
include/perfetto/ext/is internal-only and exposed only for Chromium. - A new C API/ABI for a tracing shared library is in the works in
include/perfetto/public. It is not stable yet. - The tracing protocol ABI is based on protobuf-over-UNIX-socket and shared memory. It is long-term stable and maintains compatibility in both directions (old service + newer client and vice-versa).
- The DataSourceDescriptor, DataSourceConfig and TracePacket protos are updated maintaining backwards compatibility unless a message is marked as experimental. Trace Processor deals with importing older trace formats.
- There isn't a version number neither in the trace file nor in the tracing protocol and there will never be one. Feature flags are used when necessary.
C++ API
The Client Library C++ API allows an app to contribute to the trace with custom
trace events. Its headers live under include/perfetto/.
There are three different tiers of this API, offering increasingly higher expressive power, at the cost of increased complexity. The three tiers are built on top of each other. (Googlers, for more details see also go/perfetto-client-api).
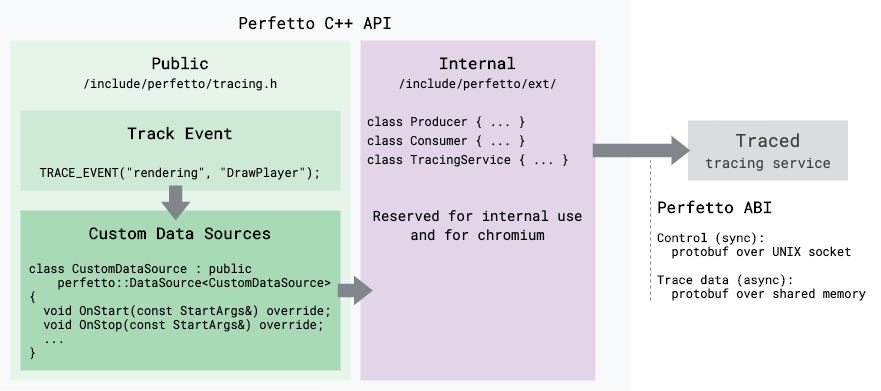
Track Event (public)
This mainly consists of the TRACE_EVENT* macros defined in
track_event.h.
Those macros provide apps with a quick and easy way to add common types of
instrumentation points (slices, counters, instant events).
For details and instructions see the Client Library doc.
Custom Data Sources (public)
This consists of the perfetto::DataSource base class and the
perfetto::Tracing controller class defined in
tracing.h.
These classes allow an app to create custom data sources which can get
notifications about tracing sessions lifecycle and emit custom protos in the
trace (e.g. memory snapshots, compositor layers, etc).
For details and instructions see the Client Library doc.
Both the Track Event API and the custom data source are meant to be a public API.
WARNING: The team is still iterating on this API surface. While we try to avoid deliberate breakages, some occasional compile-time breakages might be encountered when updating the library. The interface is expected to stabilize by the end of 2020.
Producer / Consumer API (internal)
This consists of all the interfaces defined in the
include/perfetto/ext directory. These provide access
to the lowest levels of the Perfetto internals (manually registering producers
and data sources, handling all IPCs).
These interfaces will always be highly unstable. We highly discourage any project from depending on this API because it is too complex and extremely hard to get right. This API surface exists only for the Chromium project, which has unique challenges (e.g., its own IPC system, complex sandboxing models) and has dozens of subtle use cases accumulated through over ten years of legacy of chrome://tracing. The team is continuously reshaping this surface to gradually migrate all Chrome Tracing use cases over to Perfetto.
Tracing Protocol ABI
The Tracing Protocol ABI consists of the following binary interfaces that allow various processes in the operating system to contribute to tracing sessions and inject tracing data into the tracing service:
The whole tracing protocol ABI is binary stable across platforms and is updated maintaining both backwards and forward compatibility. No breaking changes have been introduced since its first revision in Android 9 (Pie, 2018). See also the ABI Stability section below.
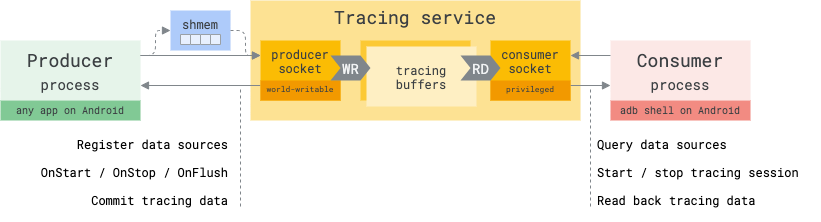
Socket protocol
At the lowest level, the tracing protocol is initiated with a UNIX socket of
type SOCK_STREAM to the tracing service.
The tracing service listens on two distinct sockets: producer and consumer.
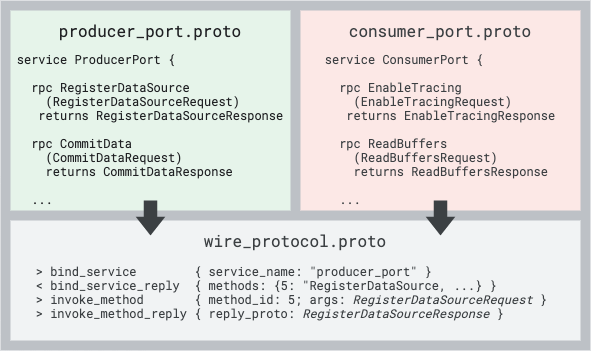
Both sockets use the same wire protocol, the IPCFrame message defined in
wire_protocol.proto. The wire
protocol is simply based on a sequence of length-prefixed messages of the form:
< 4 bytes len little-endian > < proto-encoded IPCFrame >
04 00 00 00 A0 A1 A2 A3 05 00 00 00 B0 B1 B2 B3 B4 ...
{ len: 4 } [ Frame 1 ] { len: 5 } [ Frame 2 ]The IPCFrame proto message defines a request/response protocol that is
compatible with the protobuf services syntax. IPCFrame defines
the following frame types:
BindService {producer, consumer} -> service
Binds to one of the two service ports (eitherproducer_portorconsumer_port).BindServiceReply service -> {producer, consumer}
Replies to the bind request, listing all the RPC methods available, together with their method ID.InvokeMethod {producer, consumer} -> service
Invokes a RPC method, identified by the ID returned byBindServiceReply. The invocation takes as unique argument a proto sub-message. Each method defines a pair of request and response method types.
For instance theRegisterDataSourcedefined in producer_port.proto takes aperfetto.protos.RegisterDataSourceRequestand returns aperfetto.protos.RegisterDataSourceResponse.InvokeMethodReply service -> {producer, consumer}
Returns the result of the corresponding invocation or an error flag. If a method return signature is marked asstream(e.g.returns (stream GetAsyncCommandResponse)), the method invocation can be followed by more than oneInvokeMethodReply, all with the samerequest_id. All replies in the stream except for the last one will havehas_more: true, to notify the client more responses for the same invocation will follow.
Here is how the traffic over the IPC socket looks like:
# [Prd > Svc] Bind request for the remote service named "producer_port"
request_id: 1
msg_bind_service { service_name: "producer_port" }
# [Svc > Prd] Service reply.
request_id: 1
msg_bind_service_reply: {
success: true
service_id: 42
methods: {id: 2; name: "InitializeConnection" }
methods: {id: 5; name: "RegisterDataSource" }
methods: {id: 3; name: "UnregisterDataSource" }
...
}
# [Prd > Svc] Method invocation (RegisterDataSource)
request_id: 2
msg_invoke_method: {
service_id: 42 # "producer_port"
method_id: 5 # "RegisterDataSource"
# Proto-encoded bytes for the RegisterDataSourceRequest message.
args_proto: [XX XX XX XX]
}
# [Svc > Prd] Result of RegisterDataSource method invocation.
request_id: 2
msg_invoke_method_reply: {
success: true
has_more: false # EOF for this request
# Proto-encoded bytes for the RegisterDataSourceResponse message.
reply_proto: [XX XX XX XX]
}Producer socket
The producer socket exposes the RPC interface defined in producer_port.proto. It allows processes to advertise data sources and their capabilities, receive notifications about the tracing session lifecycle (trace being started, stopped) and signal trace data commits and flush requests.
This socket is also used by the producer and the service to exchange a tmpfs file descriptor during initialization for setting up the shared memory buffer where tracing data will be written (asynchronously).
On Android this socket is linked at /dev/socket/traced_producer. On all
platforms it is overridable via the PERFETTO_PRODUCER_SOCK_NAME env var.
On Android all apps and most system processes can connect to it
(see perfetto_producer in SELinux policies).
In the Perfetto codebase, the traced_probes and
heapprofd processes use the producer socket for
injecting system-wide tracing / profiling data.
Consumer socket
The consumer socket exposes the RPC interface defined in consumer_port.proto. The consumer socket allows processes to control tracing sessions (start / stop tracing) and read back trace data.
On Android this socket is linked at /dev/socket/traced_consumer. On all
platforms it is overridable via the PERFETTO_CONSUMER_SOCK_NAME env var.
Trace data contains sensitive information that discloses the activity the system (e.g., which processes / threads are running) and can allow side-channel attacks. For this reason the consumer socket is intended to be exposed only to a few privileged processes.
On Android, only the adb shell domain (used by various UI tools like
Perfetto UI,
Android Studio or the
Android GPU Inspector)
and few other trusted system services are allowed to access the consumer socket
(see traced_consumer in SELinux).
In the Perfetto codebase, the perfetto
binary (/system/bin/perfetto on Android) provides a consumer implementation
and exposes it through a command line interface.
Socket protocol FAQs
Why SOCK_STREAM and not DGRAM/SEQPACKET?
- To allow direct passthrough of the consumer socket on Android through
adb forward localabstractand allow host tools to directly talk to the on-device tracing service. Today both the Perfetto UI and Android GPU Inspector do this. - To allow in future to directly control a remote service over TCP or SSH tunneling.
- Because the socket buffer for
SOCK_DGRAMis extremely limited and andSOCK_SEQPACKETis not supported on MacOS.
Why not gRPC?
The team evaluated gRPC in late 2017 as an alternative but ruled it out due to: (i) binary size and memory footprint; (ii) the complexity and overhead of running a full HTTP/2 stack over a UNIX socket; (iii) the lack of fine-grained control on back-pressure.
Is the UNIX socket protocol used within Chrome processes?
No. Within Chrome processes (the browser app, not CrOS) Perfetto doesn't use
any doesn't use any unix socket. Instead it uses the functionally equivalent
Mojo endpoints Producer{Client,Host} and Consumer{Client,Host}.
Shared memory
This section describes the binary interface of the memory buffer shared between a producer process and the tracing service (SMB).
The SMB is a staging area to decouple data sources living in the Producer and allow them to do non-blocking async writes. A SMB is small-ish, typically hundreds of KB. Its size is configurable by the producer when connecting. For more architectural details about the SMB see also the buffers and dataflow doc and the shared_memory_abi.h sources.
Obtaining the SMB
The SMB is obtained by passing a tmpfs file descriptor over the producer socket
and memory-mapping it both from the producer and service.
The producer specifies the desired SMB size and memory layout when sending the
InitializeConnectionRequest request to the
service, which is the very first IPC sent after connection.
By default, the service creates the SMB and passes back its file descriptor to
the producer with the InitializeConnectionResponse
IPC reply. Recent versions of the service (Android R / 11) allow the FD to be
created by the producer and passed down to the service in the request. When the
service supports this, it acks the request setting
InitializeConnectionResponse.using_shmem_provided_by_producer = true. At the
time of writing this feature is used only by Chrome for dealing with lazy
Mojo initialization during startup tracing.
SMB memory layout: pages, chunks, fragments and packets
The SMB is partitioned into fixed-size pages. A SMB page must be an integer multiple of 4KB. The only valid sizes are: 4KB, 8KB, 16KB, 32KB.
The size of a SMB page is determined by each Producer at connection time, via
the shared_memory_page_size_hint_bytes field of InitializeConnectionRequest
and cannot be changed afterwards. All pages in the SMB have the same size,
constant throughout the lifetime of the producer process.
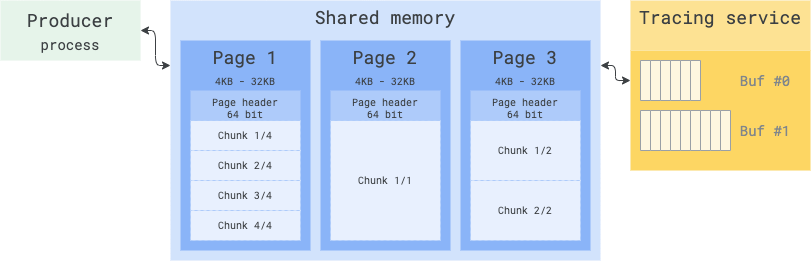
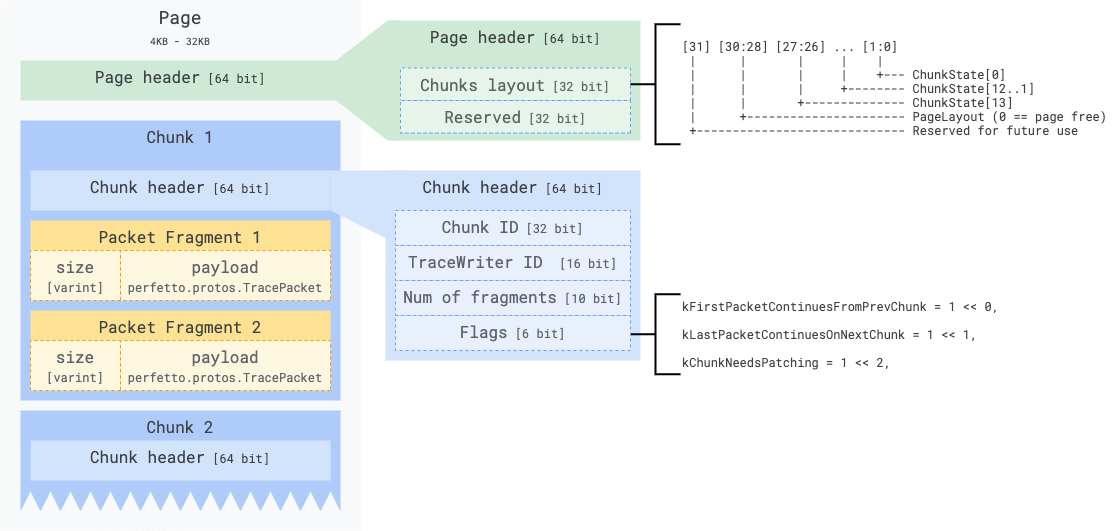
A page is a fixed-sized partition of the shared memory buffer and is just a container of chunks. The Producer can partition each Page SMB using a limited number of predetermined layouts (1 page : 1 chunk; 1 page : 2 chunks and so on). The page layout is stored in a 32-bit atomic word in the page header. The same 32-bit word contains also the state of each chunk (2 bits per chunk).
Having fixed the total SMB size (hence the total memory overhead), the page size is a triangular trade off between:
- IPC traffic: smaller pages -> more IPCs.
- Producer lock freedom: larger pages -> larger chunks -> data sources can write more data without needing to swap chunks and synchronize.
- Risk of write-starving the SMB: larger pages -> higher chance that the Service won't manage to drain them and the SMB remains full.
The page size, on the other side, has no implications on memory wasted due to fragmentation (see Chunk below).
A chunk A chunk is a portion of a Page and contains a linear sequence of
TracePacket(s) (the root trace proto).
A Chunk defines the granularity of the interaction between the Producer and
tracing Service. When a producer fills a chunk it sends CommitData IPC to the
service, asking it to copy its contents into the central non-shared buffers.
A chunk can be in one of the following four states:
Free: The Chunk is free. The Service shall never touch it, the Producer can acquire it when writing and transition it into theBeingWrittenstate.BeingWritten: The Chunk is being written by the Producer and is not complete yet (i.e. there is still room to write other trace packets). The Service never alter the state of chunks in theBeingWrittenstate (but will still read them when flushing even if incomplete).Complete: The Producer is done writing the chunk and won't touch it again. The Service can move it to its non-shared ring buffer and mark the chunk asBeingRead->Freewhen done.BeingRead: The Service is moving the page into its non-shared ring buffer. Producers never touch chunks in this state. Note: this state ended up being never used as the service directly transitions chunks fromCompleteback toFree.
A chunk is owned exclusively by one thread of one data source of the producer.
Chunks are essentially single-writer single-thread lock-free arenas. Locking happens only when a Chunk is full and a new one needs to be acquired.
Locking happens only within the scope of a Producer process.
Inter-process locking is not generally allowed. The Producer cannot lock the
Service and vice versa. In the worst case, any of the two can starve the SMB, by
marking all chunks as either being read or written. But that has the only side
effect of losing the trace data.
The only case when stalling on the writer-side (the Producer) can occur is when
a data source in a producer opts in into using the
BufferExhaustedPolicy.kStall policy and the SMB
is full.
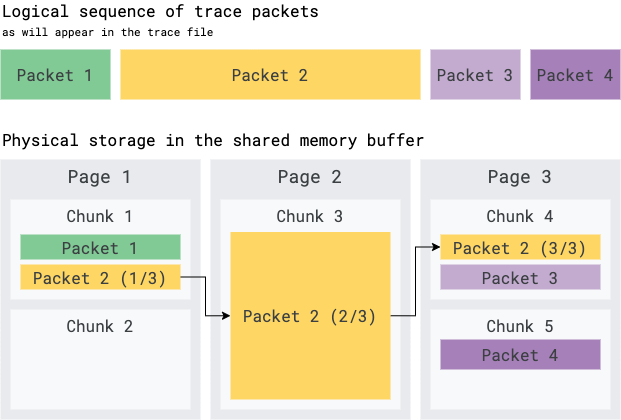
TracePacket is the atom of tracing. Putting aside pages and chunks a trace is conceptually just a concatenation of TracePacket(s). A TracePacket can be big (up to 64 MB) and can span across several chunks, hence across several pages. A TracePacket can therefore be >> chunk size, >> page size and even >> SMB size. The Chunk header carries metadata to deal with the TracePacket splitting.
Overview of the Page, Chunk, Fragment and Packet concepts:
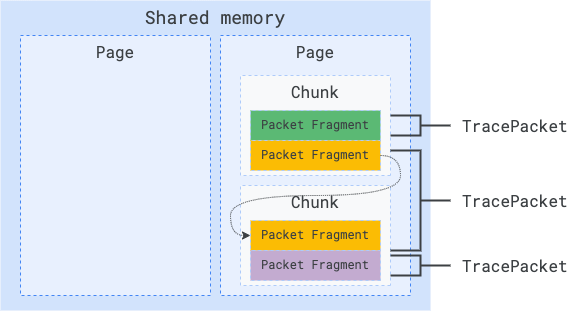
Memory layout of a Page:
Because a packet can be larger than a page, the first and the last packets in a chunk can be fragments.
Post-facto patching through IPC
If a TracePacket is particularly large, it is very likely that the chunk that contains its initial fragments is committed into the central buffers and removed from the SMB by the time the last fragments of the same packets is written.
Nested messages in protobuf are prefixed by their length. In a zero-copy direct-serialization scenario like tracing, the length is known only when the last field of a submessage is written and cannot be known upfront.
Because of this, it is possible that when the last fragment of a packet is written, the writer needs to backfill the size prefix in an earlier fragment, which now might have disappeared from the SMB.
In order to do this, the tracing protocol allows to patch the contents of a
chunk through the CommitData IPC (see
CommitDataRequest.ChunkToPatch) after the tracing
service copied it into the central buffer. There is no guarantee that the
fragment will be still there (e.g., it can be over-written in ring-buffer mode).
The service will patch the chunk only if it's still in the buffer and only if
the producer ID that wrote it matches the Producer ID of the patch request over
IPC (the Producer ID is not spoofable and is tied to the IPC socket file
descriptor).
Proto definitions
The following protobuf messages are part of the overall trace protocol ABI and are updated maintaining backward-compatibility, unless marked as experimental in the comments.
TIP: See also the Updating A Message Type section of the Protobuf Language Guide for valid ABI-compatible changes when updating the schema of a protobuf message.
DataSourceDescriptor
Defined in data_source_descriptor.proto. This message is sent Producer -> Service through IPC on the Producer socket during the Producer initialization, before any tracing session is started. This message is used to register advertise a data source and its capabilities (e.g., which GPU HW counters are supported, their possible sampling rates).
DataSourceConfig
Defined in data_source_config.proto. This message is sent:
Consumer -> Service through IPC on the Consumer socket, as part of the TraceConfig when a Consumer starts a new tracing session.
Service -> Producer through IPC on the Producer socket, as a reaction to the above. The service passes through each
DataSourceConfigsection defined in theTraceConfigto the corresponding Producer(s) that advertise that data source.
TracePacket
Defined in trace_packet.proto. This is the root object written by any data source into the SMB when producing any form of trace event. See the TracePacket reference for the full details.
ABI Stability
All the layers of the tracing protocol ABI are long-term stable and can only be changed maintaining backwards compatibility.
This is due to the fact that on every Android release the traced service
gets frozen in the system image while unbundled apps (e.g. Chrome) and host
tools (e.g. Perfetto UI) can be updated at a more frequently cadence.
Both the following scenarios are possible:
Producer/Consumer client older than tracing service
This happens typically during Android development. At some point some newer code is dropped in the Android platform and shipped to users, while client software and host tools will lag behind (or simply the user has not updated their app / tools).
The tracing service needs to support clients talking and older version of the Producer or Consumer tracing protocol.
- Don't remove IPC methods from the service.
- Assume that fields added later to existing methods might be absent.
- For newer Producer/Consumer behaviors, advertise those behaviors through
feature flags when connecting to the service. Good examples of this are the
will_notify_on_stoporhandles_incremental_state_clearflags in data_source_descriptor.proto
Producer/Consumer client newer than tracing service
This is the most likely scenario. At some point in 2022 a large number of phones
will still run Android P or Q, hence running a snapshot of the tracing service
from ~2018-2020, but will run a recent version Google Chrome.
Chrome, when configured in system-tracing mode (i.e. system-wide + in-app
tracing), connects to the Android's traced producer socket and talks the
latest version of the tracing protocol.
The producer/consumer client code needs to be able to talk with an older version of the service, which might not support some newer features.
Newer IPC methods defined in producer_port.proto won't exist in the older service. When connecting on the socket the service lists its RPC methods and the client is able to detect if a method is available or not. At the C++ IPC layer, invoking a method that doesn't exist on the service causes the
Deferred<>promise to be rejected.Newer fields in existing IPC methods will just be ignored by the older version of the service.
If the producer/consumer client depends on a new behavior of the service, and that behavior cannot be inferred by the presence of a method, a new feature flag must be exposed through the
QueryCapabilitiesmethod.
Static linking vs shared library
The Perfetto C++ Client Library is only available in the form of a static library and a single-source amalgamated SDK (which is effectively a static library). The library implements the Tracing Protocol ABI so, once statically linked, depends only on the socket and shared memory protocol ABI, which are guaranteed to be stable.
No shared library distributions for the C++ are available. We strongly discourage teams from attempting to build the C++ tracing library as shared library and use it from a different linker unit. It is fine to link AND use the client library within the same shared library, as long as none of the perfetto C++ API is exported.
The PERFETTO_EXPORT_COMPONENT annotations are only used when building the
third tier of the client library in chromium component builds and cannot be
easily repurposed for delineating shared library boundaries for the other two
API tiers.
This is because the C++ the first two tiers of the Client Library C++ API make extensive use of inline headers and C++ templates, in order to allow the compiler to see through most of the layers of abstraction.
Maintaining the C++ ABI across hundreds of inlined functions and a shared library is prohibitively expensive and too prone to break in extremely subtle ways. For this reason the team has ruled out shared library distributions for the time being.
A new C Client library API/ABI is in the works, but it's not stable yet.